template = """{
"output": {
"entities": ["string"],
"relationships": [["string", "string", "string"]]
}
}"""
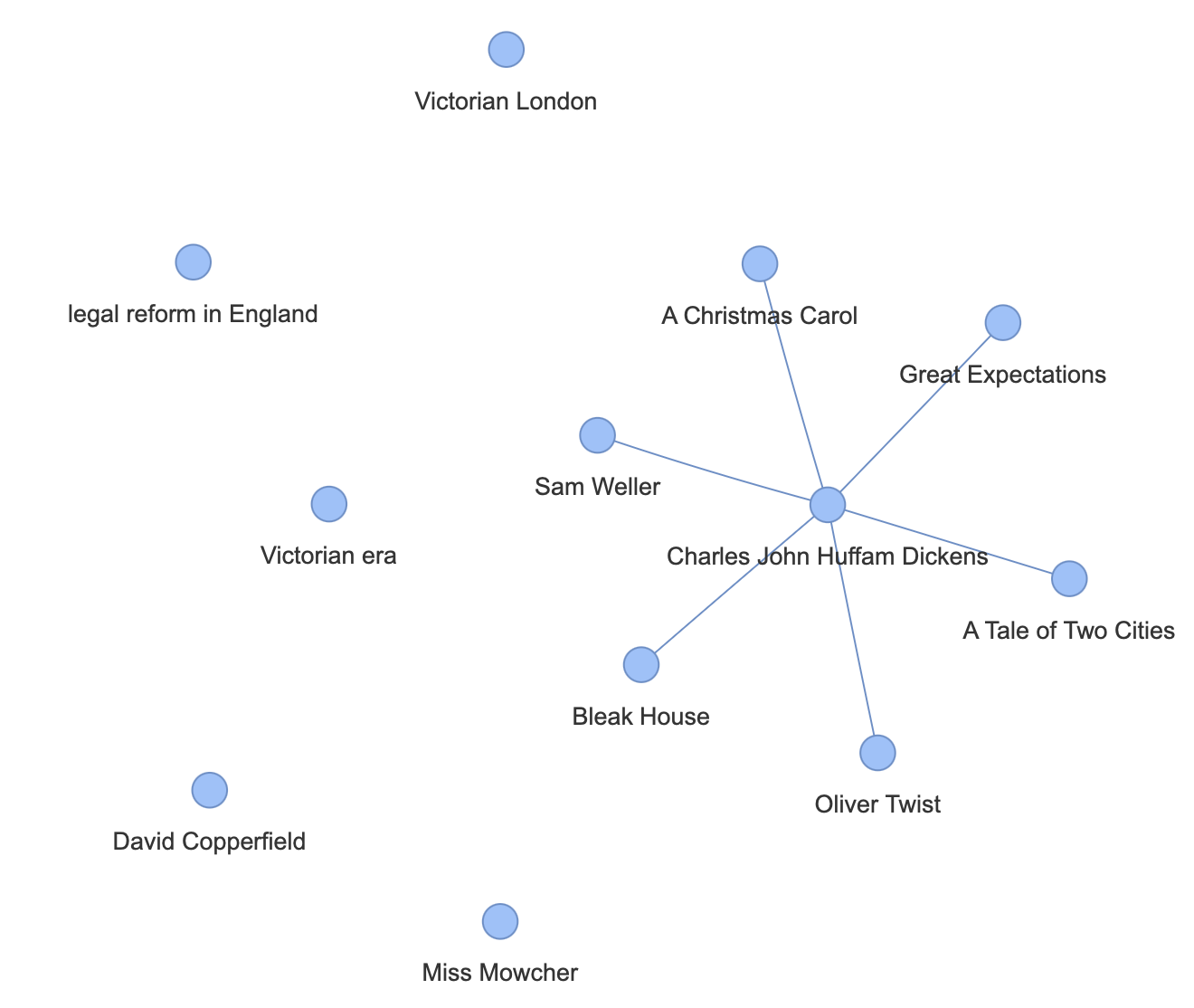
document = """Charles John Huffam Dickens (7 February 1812 – 9 June 1870) was an English novelist, journalist, short story writer and social critic. He created some of literature's best-known fictional characters, and is regarded by many as the greatest novelist of the Victorian era. His works enjoyed unprecedented popularity during his lifetime and, by the 20th century, critics and scholars had recognised him as a literary genius. His novels and short stories are widely read today.
Born in Portsmouth, Dickens left school at age 12 to work in a boot-blacking factory when his father John was incarcerated in a debtors' prison. After three years, he returned to school before beginning his literary career as a journalist. Dickens edited a weekly journal for 20 years; wrote 15 novels, five novellas, hundreds of short stories and nonfiction articles; lectured and performed readings extensively; was a tireless letter writer; and campaigned vigorously for children's rights, education and other social reforms.
Dickens's literary success began with the 1836 serial publication of The Pickwick Papers, a publishing phenomenon—thanks largely to the introduction of the character Sam Weller in the fourth episode—that sparked Pickwick merchandise and spin-offs. Within a few years, Dickens had become an international literary celebrity, famous for his humour, satire and keen observation of character and society. His novels, most of them published in monthly or weekly instalments, pioneered the serial publication of narrative fiction, which became the dominant Victorian mode for novel publication. Cliffhanger endings in his serial publications kept readers in suspense. The instalment format allowed Dickens to evaluate his audience's reaction, and he often modified his plot and character development based on such feedback. For example, when his wife's chiropodist expressed distress at the way Miss Mowcher in David Copperfield seemed to reflect her own disabilities, Dickens improved the character with positive features. His plots were carefully constructed and he often wove elements from topical events into his narratives. Masses of the illiterate poor would individually pay a halfpenny to have each new monthly episode read to them, opening up and inspiring a new class of readers.
His 1843 novella A Christmas Carol remains especially popular and continues to inspire adaptations in every creative medium. Oliver Twist and Great Expectations are also frequently adapted and, like many of his novels, evoke images of early Victorian London. His 1853 novel Bleak House, a satire on the judicial system, helped support a reformist movement that culminated in the 1870s legal reform in England. A Tale of Two Cities (1859; set in London and Paris) is regarded as his best-known work of historical fiction. The most famous celebrity of his era, he undertook, in response to public demand, a series of public reading tours in the later part of his career. The term Dickensian is used to describe something that is reminiscent of Dickens and his writings, such as poor social or working conditions, or comically repulsive characters."""
examples = [
{
"input": "Stephen is the manager of Anna. Stephen works in Belgium.",
"output": """{
"entities": ["Stephen", "Anna", "Belgium"],
"relationships": [["Stephen", "manager_of", "Anna"],
["Stephen", "works_in", "Belgium"]]
}"""
},
{
"input": "Google was founded by Larry Page and Sergey Brin while they were Ph.D. students at Stanford University.",
"output": """{
"entities": ["Google", "Larry Page", "Sergey Brin", "Stanford University"],
"relationships": [["Larry Page", "co_founder_of", "Google"],
["Sergey Brin", "co_founder_of", "Google"],
["Larry Page", "student_at", "Stanford University"],
["Sergey Brin", "student_at", "Stanford University"]]
}"""
}
]
messages = [{"role": "user", "content": document}]
text = processor.tokenizer.apply_chat_template(
messages,
template=template,
examples=examples, # examples provided here
tokenize=False,
add_generation_prompt=True,
)
inputs = processor(
text=[text],
images=None,
padding=True,
return_tensors="pt",
)
inputs = inputs.to(model.device)
start_time = time.time()
# https://huggingface.co/docs/transformers/main_classes/text_generation
generated_ids = model.generate(
**inputs,
**{
"do_sample": False, # False means greedy decoding
"num_beams": 1,
"max_new_tokens": 2*4096,
"temperature": None,
"top_p": None,
"top_k": None,
# "max_time": 120,
}
)
end_time = time.time()
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
result = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
try:
g = json.loads(result[0])
print(json.dumps(g, indent=4))
print(f"Found {len(g['entities']) if 'entities' in g else 0} entities and {len(g['relationships']) if 'relationships' in g else 0} relationships in {(end_time - start_time):.1f} seconds.")
except json.JSONDecodeError as e:
print("Bad format JSON output:", result[0])