Graph RAG
Over the past two years, I’ve explored Retrieval-Augmented Generation (RAG) and its intersection with graph-based systems. While the field of AI has seen dramatic advancements during this time, certain foundational principles remain relevant and stable. This article highlights those principles and explains how to build a robust graph RAG solution, emphasizing clarity and accessibility over technical depth. Although including code could simplify some explanations, I’ve deliberately avoided it to keep the content approachable for non-technical readers.
Keeping the Focus Broad and Flexible
The ecosystem surrounding RAG is vast, with a multitude of frameworks, tools, and databases. My aim is to provide a conceptual understanding rather than focusing on specific tools or implementations. For example, knowledge graphs can be stored in numerous formats—graph databases, relational databases, or even document stores. Similarly, frameworks like LangChain, LlamaIndex, or Crew AI simplify agent-based implementations but aren’t essential to understanding the core principles. I encourage practitioners to begin without relying heavily on frameworks to grasp the finer details. Frameworks are powerful but can obscure the underlying mechanisms.
While the implementation of RAG relies on a language model (LLM), the specifics of the LLM used—whether it’s running locally (e.g., Ollama) or via a hosted service—are secondary to the conceptual structure. At the time of writing, I favor models like Qwen 2.5, but the landscape evolves rapidly. In a year, we may see models capable of rendering knowledge graphs dynamically and reasoning over them in real time.
Introduction: The Challenge of Limited Context in LLMs
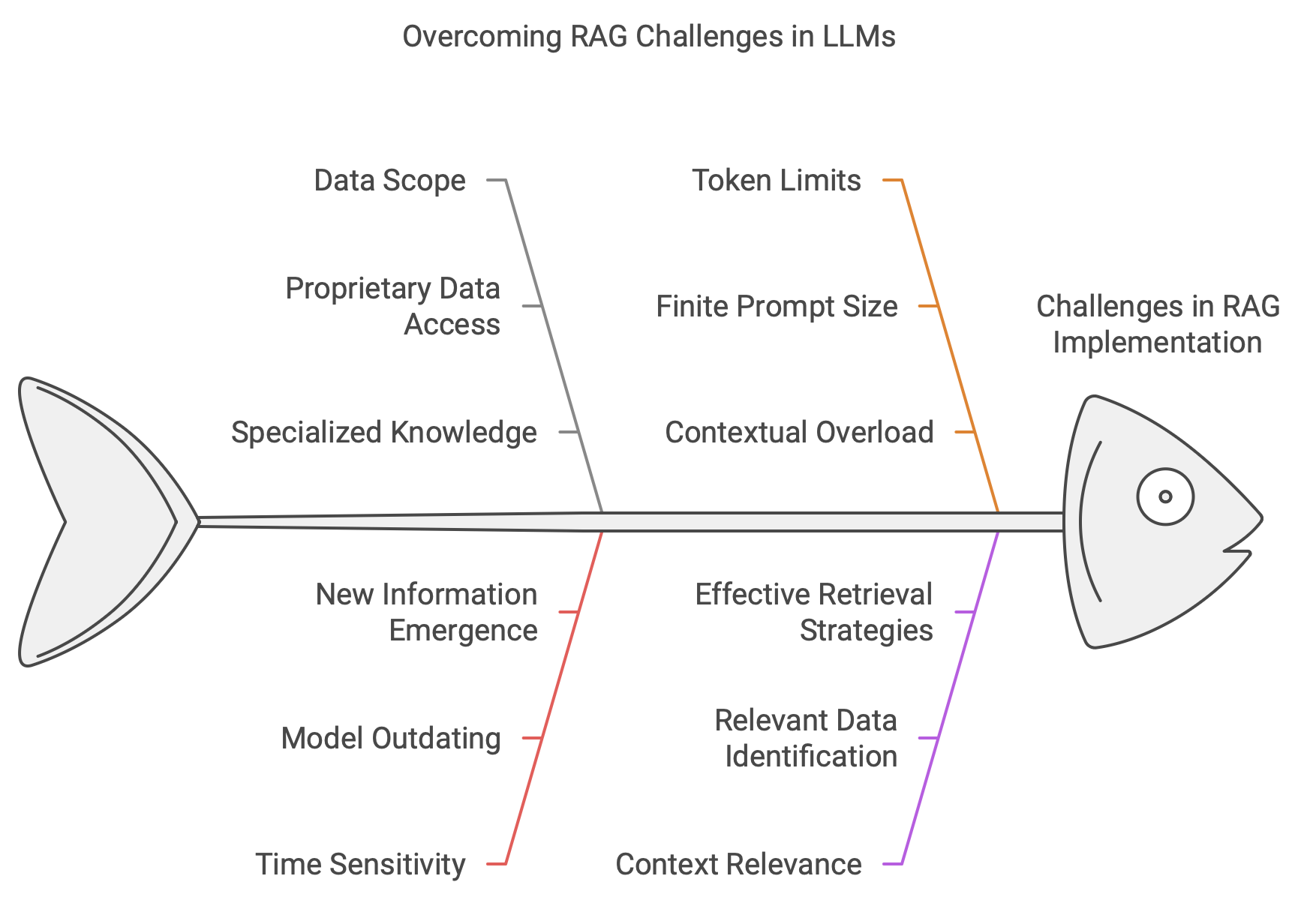
At its core, the issue we address with RAG stems from the limitations of LLMs. These models are trained on a fixed corpus of data at a specific point in time. This creates two major constraints:
- Data Scope: LLMs cannot access proprietary, specialized, or private data unless explicitly provided.
- Time Sensitivity: Models become outdated as new information emerges.
The good news is that LLMs are designed to incorporate additional information when it’s included in a prompt. This is the essence of Retrieval-Augmented Generation (RAG). By retrieving and supplying relevant context to the LLM during inference, companies can utilize LLMs with their private or proprietary data without retraining or exposing sensitive information.
However, RAG introduces its own challenges:
- Token Limits: LLMs have finite prompt sizes, limiting the amount of contextual information you can provide.
- Context Relevance: How do you identify and retrieve the most relevant information to include in the prompt?
These challenges divide the problem into two main areas:
- Retrieval: Identifying the data relevant to a query.
- Prompting: Formatting the retrieved data to maximize LLM performance.
The development of prompt engineering has emerged as a distinct discipline, focused on crafting input formulations that elicit accurate and predictable responses from LLMs. This process is inherently model-specific, with each LLM exhibiting unique characteristics that render universal prompting strategies ineffective. Consequently, efforts to codify and standardize prompt engineering have been undertaken (see e.g. DSPY), albeit with varying degrees of success. Notwithstanding these challenges, the efficacy of well-crafted prompts in yielding high-quality responses remains a consistent truth, regardless of the context from which they are derived.️
How to retrieve (business) data relevant to a question is where knowledge graphs enter the picture. The problem is in fact independent of LLMs: given a question, how to query and retrieve information from a repository relevant to the question? Systems like Confluence, Sharepoint and others index documents and much like a table of contents or the index in a book, they return a list based on indexing and keyword matches. Frameworks like Apache Lucene have been integrated in countless systems to this end. This is the approach from the 20th century and has been superseded by vectors and embeddings.
The advent of machine learning has introduced a paradigm shift in natural language processing (NLP), predicated upon the concept of utilizing vectors to encapsulate linguistic information. While traditional NLP methodologies have long employed techniques such as chunking and tokenizing, which involve dissecting text into constituent parts, this approach remains relevant within the context of large language models.
In contrast, the notion of text vectors represents a novel approach to NLP, wherein the focus shifts from analytical examination of syntax, grammatical structure, coreference, and other linguistic phenomena to a more holistic treatment of language as a classification and feature engineering problem. By creating comprehensive vectors for words, this methodology ensures that pertinent information is preserved. The underlying principle is that text can be regarded as a numerical construct, analogous to an image being represented by a sequence of RGB values. Furthermore, the resultant vectors exhibit a degree of independence from their original textual context, capturing the essence of language in a manner akin to how children absorb and later specialize in linguistic terminology throughout their lives.️
The process of converting linguistic inputs into vector representations enables facile comparison and analysis. This methodology allows for the identification of semantic relationships between words, such as those linking “child” and “parents”, and facilitates the quantification of their proximity. In contrast, direct comparisons of words are often impractical due to their inherent complexity. Prior to the advent of LLMs, knowledge graphs and bases were constructed by domain experts to establish connections between concepts. However, this approach was labor-intensive and prone to errors, as it relied on manual curation. The development of biochemical and oncological knowledge bases exemplifies this challenge, requiring painstaking effort from human experts. These knowledge bases, while valuable, are often difficult to query and maintain due to their complexity. In response, a distinct academic discipline emerged, encompassing knowledge management, ontologies, SPARQL, and SHACL. Notably, the advent of LLM-based approaches has largely supplanted these traditional methodologies, offering a more efficient and effective means of information representation and retrieval.️
The advent of vectorized knowledge enables the comparison of semantic representations, thereby facilitating the identification of related concepts and entities. This approach obviates the need for explicit knowledge graphs or indexing systems, instead leveraging the inherent relationships between vectors to reveal connections.
For instance, when applied to a dataset containing information on climate change, this methodology can uncover associations between CO2 emissions and sea level rise, among other topics, without the necessity of manual graph construction. This technique underlies the transformative potential of artificial intelligence, empowering innovative applications and insights.
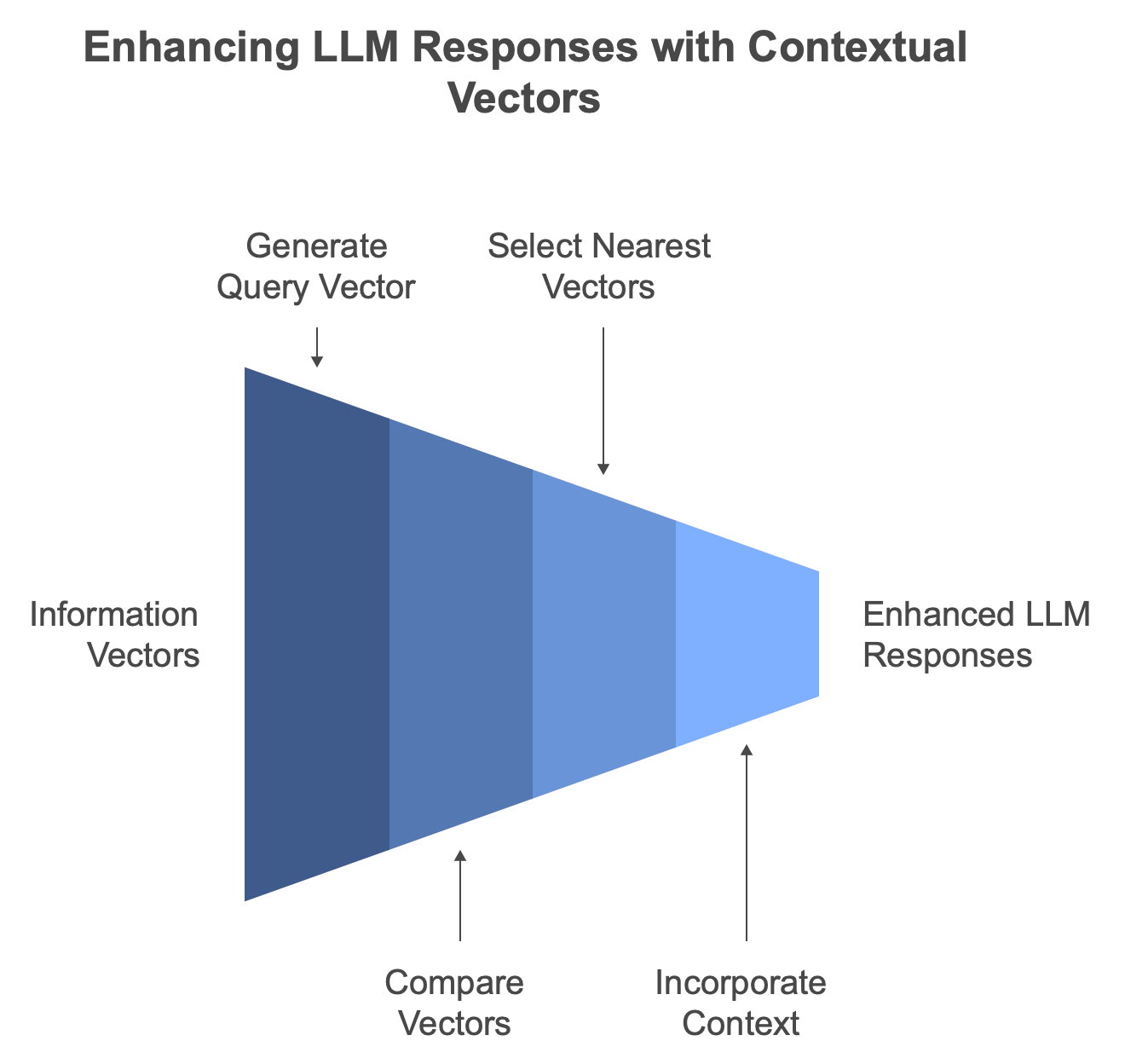
With vectorized knowledge in place, it becomes straightforward to extract relevant context from an information base to support a LLM. The process involves:
- Utilizing a vast collection of vectors representing various pieces of information.
- Generating a vector for the query or question at hand.
- Comparing the query vector with the existing information-based vectors.
- Selecting a set of similar words, paragraphs, or sentences, commonly referred to as k-nearest vectors/words/paragraphs.
- Incorporating these contextual elements into the LLM prompt to inform and enhance its responses.️
Transcending traditional NLP methodologies involves seamlessly transitioning between text and vectors, thereby circumventing the need for programmatic or analytical processing. This approach enables rapid and accurate information retrieval. The technical complexities associated with this paradigm are multifaceted; however, they can be effectively managed through a simple download and minimal coding requirements, allowing for efficient text analysis via vectorization.
While this article primarily focuses on text-based applications, it is essential to note that the concept of vectorizing information is inherently generic. Recent advancements have enabled the embedding of various forms of data, including audio, video, and protein structures, into vectorized formats. Furthermore, multi-modal models have been developed, which can uniformly process and analyze all media types, thereby expanding the scope of this technology.️
The concept of retrieving context via text embedding is referred to as Basic Retrieval-Augmentation-Generation (RAG). This approach can be implemented in a relatively short code snippet and has been extensively modified and adapted by numerous developers. The storage and comparison of vectors have also given rise to an entire industry, with various vector databases and database systems that incorporate vector capabilities being widely available.
Most relational database vendors have integrated vector indexes or developed plugins to support this functionality. Furthermore, the NoSQL movement’s emphasis on multi-modal data stores (key-value, document, graph) has led to the incorporation of vectors and embeddings into these systems.
In conjunction with bot and agentic frameworks, the RAG mechanism has enabled the creation of numerous corporate bots and applications that allow users to access information bases via natural language. However, it has been observed that this approach does not function optimally, primarily due to the inherent ambiguity of words and sentences.
The term “apple,” for instance, can refer to a fruit, a corporate entity, or stock information, among other possibilities. Consequently, when retrieving information related to “apple” from a typical database, users may receive an excessive amount of data on both the fruit and the stock market. This has resulted in confusing responses from corporate bots, not to mention issues with hallucinations.️
The crux of the matter lies not in the contextual information provided to a LLM, but rather in the context of the query itself. To furnish an LLM with the requisite context, one must first comprehend the underlying intent behind the question. For instance, a query regarding the caloric content of an apple would necessitate an understanding that this pertains to fruit, whereas a request for pricing information likely relates to stock valuation.
This dichotomy underscores two primary concerns: how to store contextual information and how to retrieve it effectively. It is at this juncture that knowledge graphs and graph-based Retrieval Augmented Generation (RAG) come into play, offering a solution to the accuracy and context-related issues inherent in naive RAG approaches.
Studies and commercial entities have substantiated the subjective experience of bots providing inaccurate responses, often with vested interests tied to the promotion of graph databases. The efficacy of text-to-SQL, naive RAG, graph RAG, and their variants can be quantitatively measured, underscoring the commercial appeal of these technologies.
The utility of graphs in this context may seem counterintuitive at first, as one might expect vectorization to provide a suitable solution. However, attaching context to vectors proves challenging, as words like ‘apple’ assume unique vector representations independent of their contextual usage. This leads to a situation where the same word can be situated within multiple topic clusters, necessitating the capture of entities or concepts and the attachment of contextual information.
Graphs excel in this regard by capturing the affinity between entities while also highlighting the importance of context. The question of how to create knowledge graphs and interrogate them via LLMs is the central focus of this article.️
What is a knowledge graph?
The concept of a knowledge graph can be succinctly defined as an organizational framework for structured data, represented in a graph-like structure. This differs from relational databases, which implicitly create graphs but do not explicitly utilize them.
However, the notion of a knowledge graph is more complex and encompasses various knowledge cultures, including semantic stacks, property graphs, strongly typed graphs, ontologies, document stores, and others. These different approaches enable diverse methods for storing and organizing data as graphs, each with its own strengths and weaknesses.
Key elements that distinguish knowledge graphs from other data storage systems include:
- The concept of traversals: Knowledge graphs prioritize the traversal of data as a graph, returning results in a graph format. In contrast, relational databases store and query data as tables.
- Graph-specific metrics: Centrality, hops, connected components, and similar measures are unique to knowledge graphs and not found in key-value stores or document stores.
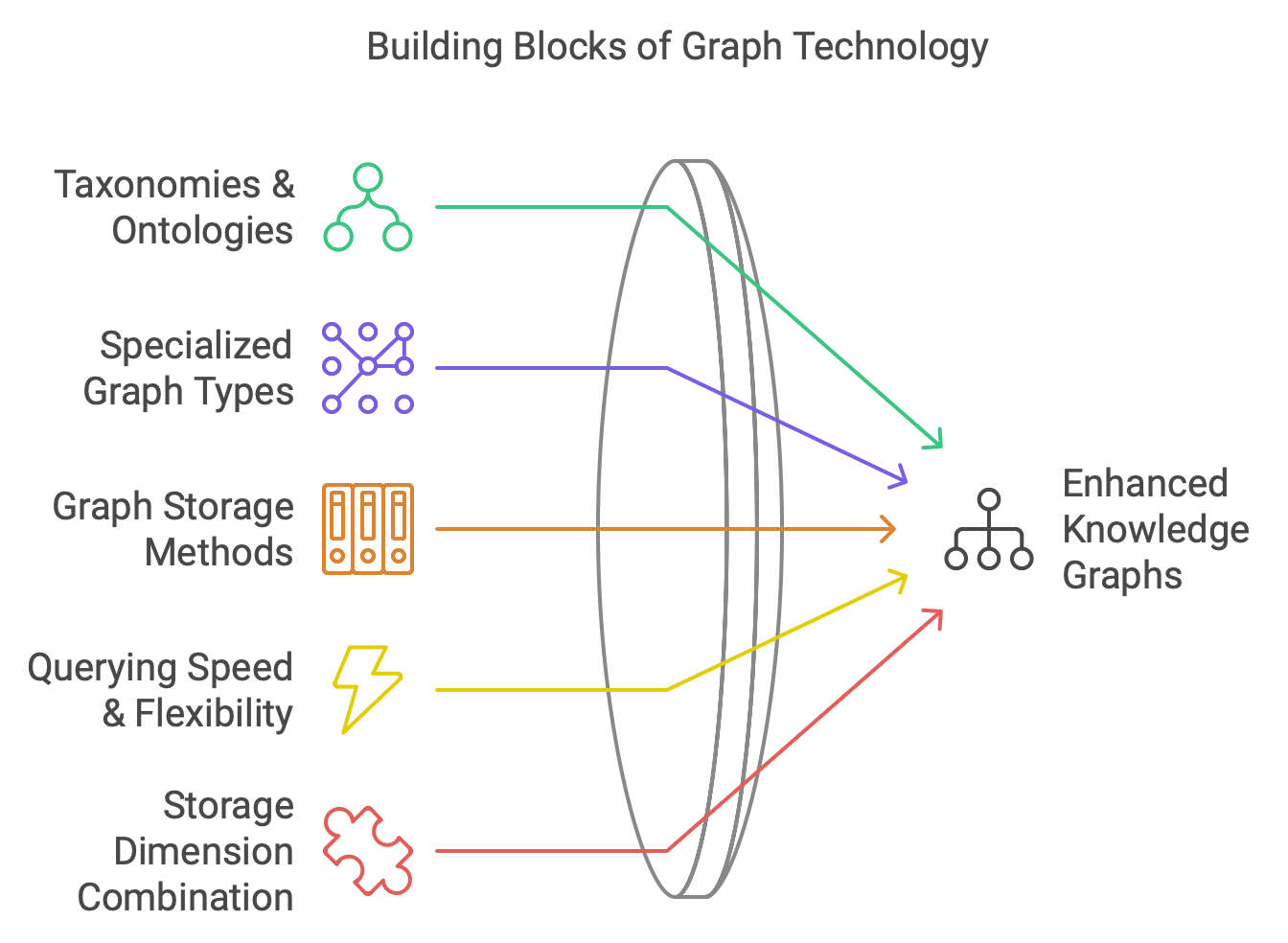
Additional concepts that are relevant to knowledge graphs include:
- Taxonomies and ontologies, which can be beneficial but also burdensome
- Hypergraphs, temporal graphs, geospatial graphs, and other specialized graph types
- The various methods for storing and scaling graph storage
- Querying speed and flexibility
- Combining storage dimensions, such as vectors, documents, and graphs️
The significance of various features and functionalities often varies depending on the specific requirements and objectives of a particular business, research initiative, or project. Database vendors typically emphasize the capabilities that are most relevant to their industry, while academic researchers focus on aspects that contribute to the advancement of knowledge or enhance their professional reputation.
Similarly, cloud service providers tend to highlight the scalability and speed of their offerings. However, when it comes to developing a proof-of-concept (POC) or minimum viable product (MVP), the need for sophisticated infrastructure is not always necessary.
In fact, a POC or MVP can be effectively developed without incurring significant expenses. The following section outlines some essential Python components that can be used to establish a solid graph-based reasoning and analytics (RAG) solution, thereby facilitating the creation of a functional POC at minimal cost.
For the purposes of this discussion, I will refer to a knowledge graph as a data structure comprising named entities and relationships between them. This definition is independent of how such a graph is stored or queried, and it provides a useful framework for exploring various operationalization and implementation strategies.️
Creating Knowledge Graphs
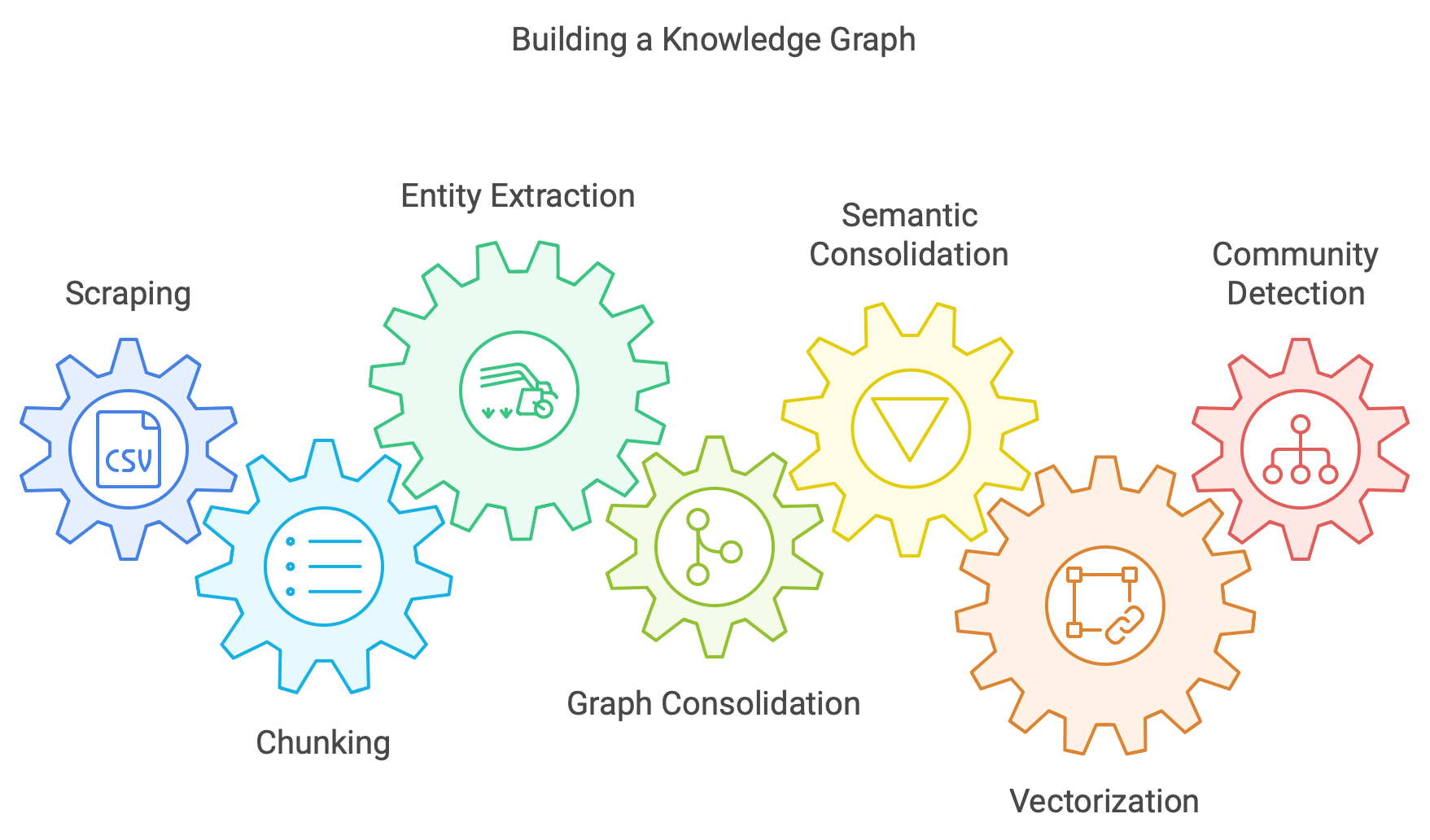
The recipe for ingesting data into a knowledge graph consists of the following steps:
- Scraping: raw information, typically in the form of PDFs, is extracted and parsed into markdown format. Each raw source is referred to as a document.
- Chunking: documents are subsequently divided into smaller components, known as chunks or nodes (although this terminology does not yet relate to graph structures).
- Entity extraction: the named entities within each chunk, along with their relationships, are identified and extracted. This process involves consolidating duplicate entity references across multiple chunks.
- Graph consolidation: the resulting entities and relationships form the foundation of the knowledge graph, with metadata retained for referencing original chunk and document sources.
- Semantic consolidation: as new chunks are extracted, the knowledge graph expands accordingly, with descriptions truncated if necessary to maintain data integrity.
- Vectorize everything: the nodes, edges, and chunks within the knowledge graph are then vectorized, enabling cross-referencing and tracking of information origins.
- Variations on this process may necessitate community detection algorithms, such as the Louvain algorithm, which is discussed in further detail in the appendix.
The following sections will provide a detailed explanation of each step in this process.️
What is being ingested?
Text is a natural source for the majority of LLMs but graph RAG can handle any type of data provided: - you have a multi-modal LLM capable of extracting topics/entities from the medium - the raw data (say, images or audio) is stored appropriately in a way it can be picked up in the same what that text is referenced - the raw data can be vectorized or embedded.
In many cases it means that you need multiple LLMs. Call it a multi-agent system with each agent coupled to a LLM for a specific task.
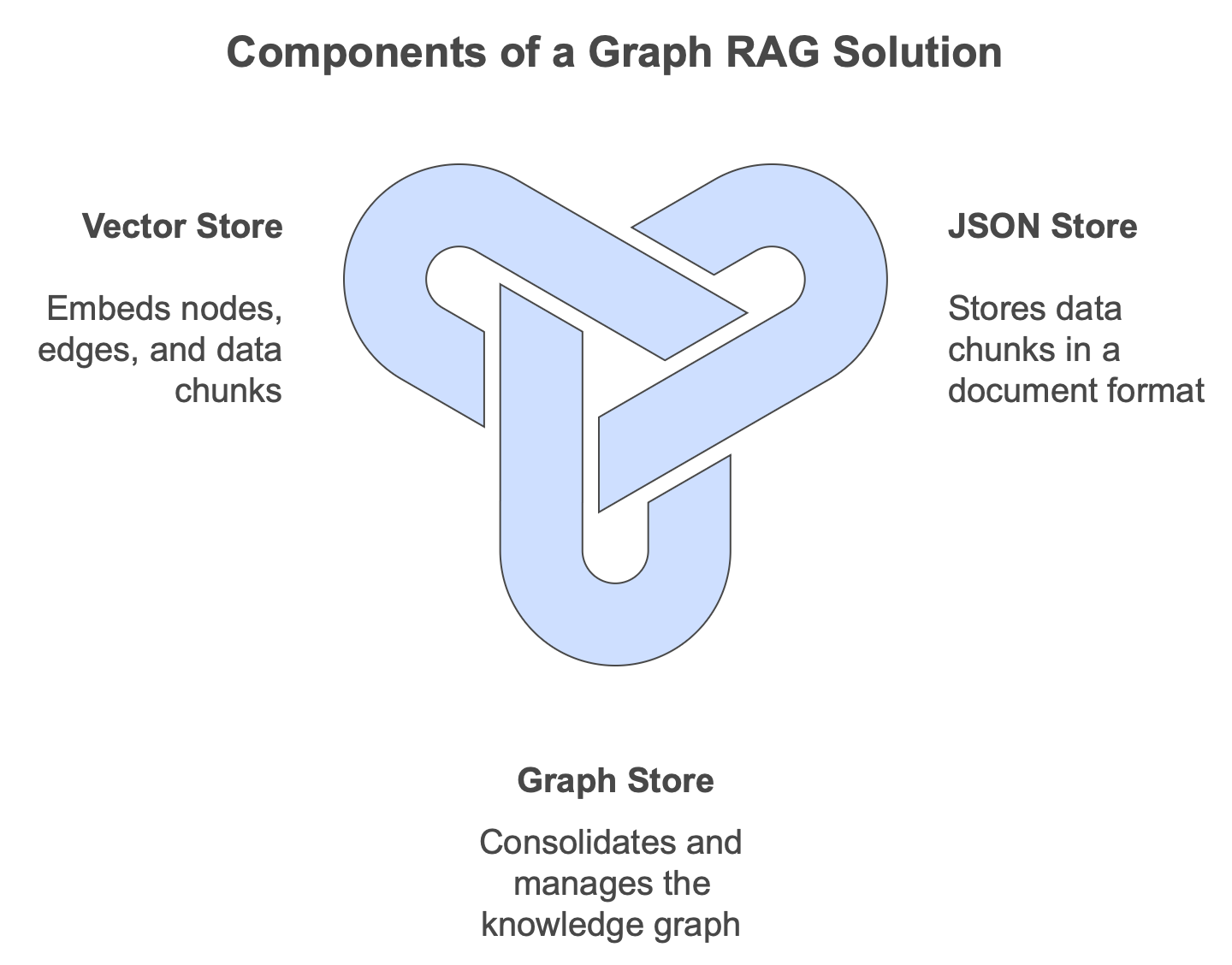
Storage
You need three storage flavors to run a graph RAG solution:
- JSON or document store to save the chunks
- a graph store to, well, consolidate the knowledge graph
- a vector store to embed nodes, edges and chunks.
You can combine the stores and solutions like Neo4j can store graphs and vectors uniformly. Or even all in one via stores like Unum. I often use ChromaDB for prototyping and NetworkX for graphs in memory. Graph RAG is really an architecture and does not depend on a particular technology, despite all the marketing claims.
Documents, chunks, tokens and all that
The optimal size of a document or text segment for referencing purposes lies between the extremes of a single sentence and a comprehensive, thousand-page document. A paragraph typically represents the most suitable chunk size, as it strikes a balance between conciseness and contextual richness.
However, determining the ideal chunk size often involves a degree of artistry rather than strict scientific calculation, as it can vary significantly depending on the specific business requirements and the nature of the raw data being processed.
Specialized techniques such as semantic chunking, character splitters can greatly enhance the effectiveness of text segmentation. For instance, when dealing with diverse corpora, employing different chunking strategies for distinct sources may be necessary to achieve optimal results.
Ultimately, the goal is to produce a collection of manageable chunks that retain references to their original sources. These references serve as verifiable anchors, enabling users to fact-check answers directly from the underlying data if needed. This process, known as grounding, provides a simple yet reliable means of detecting potential hallucinations and ensuring the accuracy of responses.
The importance of metadata
Metadata matters especially if the raw data is not text but in general:
- you need a reference from a chunk to the (parent) document
- the entities need one or more references to the chunks where they appear
- the relationships need a reference to one or more chunks where they were discovered
- the embedding of nodes, edges and chunks needs to have a reference.
The metadata isn’t just for end-user references, grounding and remembering how things got created, it matters also if you wish to delete documents or chunks. The removal of documents and chunks needs to cascade to all secondary elements in order to keep the integrity of the data.
Scraping and formats
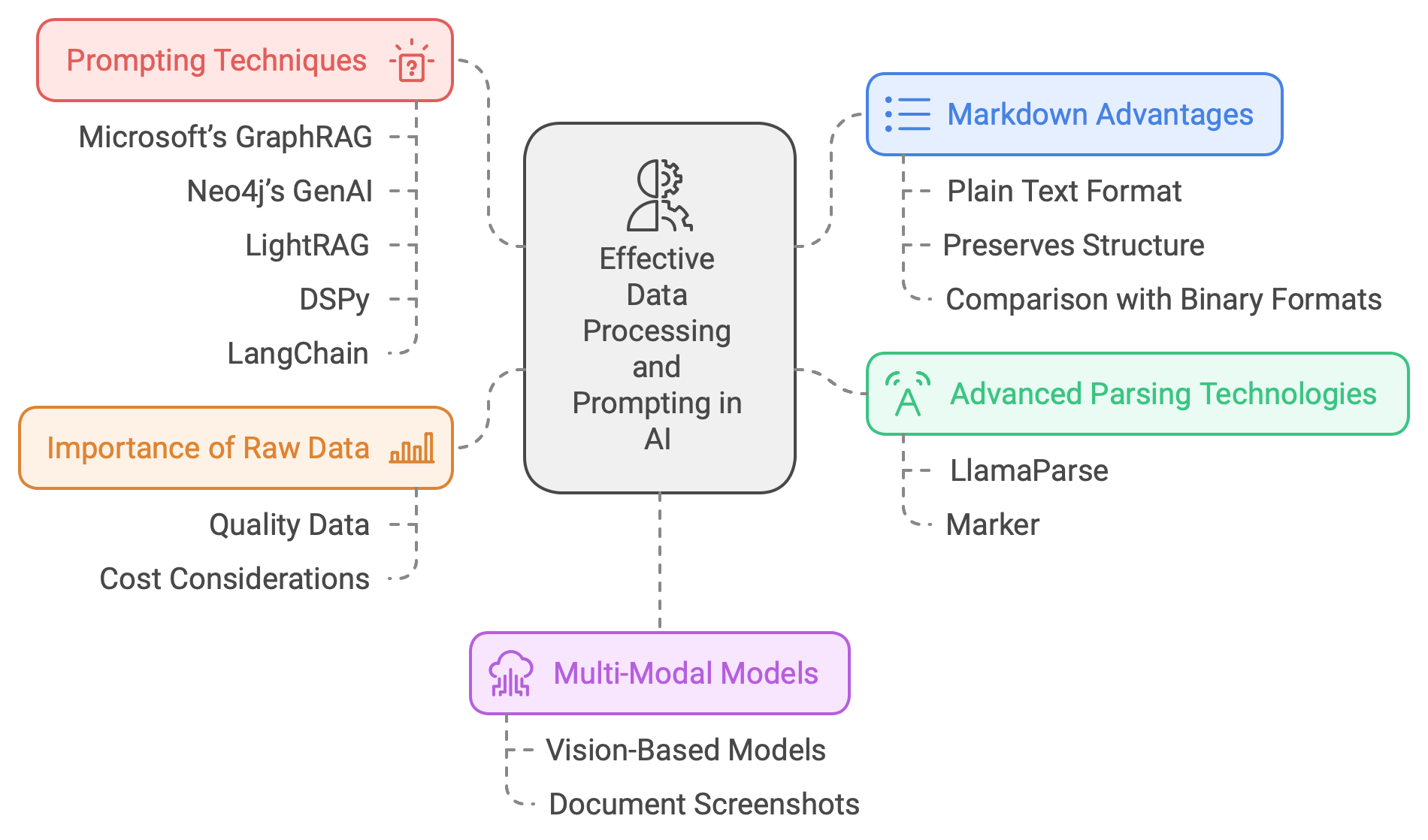
Markdown is ideal for AI because it’s plain text while preserving structure. Unlike binary large objects (blobs) and pdf’s where the binary format has to be transformed or scraped. This is also a business on its own and the technology has tremendously improved beyond basic OCR. Services like LlamaParse return quality markdown from fairly complex documents. The open source Marker project also deliver astounding results.
Since the quality of the raw data is the basis of a good knowledge graph it matters to investigate the various options and cost.
It is also worth noting that multi-modal models and vision-based models can be beneficial in this context. Providing a screenshot of a PDF document and requesting a structured output (headers, footnotes, etc.) can often yield satisfactory results. The effectiveness of this approach, however, ultimately depends on the specific business domain and the characteristics of the documents being processed. In some cases, particularly those involving complex tables, formulas, or quoted text, more advanced quality parsing may be required to achieve accurate output.️
Prompting
It is with some reluctance that I acknowledge the pivotal role played by carefully crafted prompts in the efficacy of graph RAG (and numerous other sophisticated AI applications). A thorough examination of Microsoft’s GraphRAG, Neo4j’s GenAI, LightRAG, and various graph RAG variants reveals that their success or failure is largely contingent upon the precision and effectiveness of their respective prompts.
Several techniques, such as DSPy, have been developed to treat prompting as a traditional machine learning task; however, its reliability has yet to be conclusively established. Companies like LangChain have created tools and applications that utilize agents (Large Language Models) to iteratively generate prompts. Notably, the efficiency of a prompt is heavily dependent on the specific LLM employed. Consequently, prompting remains an indispensable component and a nuanced craft, rather than a clearly defined or universally applicable formula for success.️
Entities
Extracting entities from chunks can be done in various ways:
- there are dedicated models like NuNER, NuExtract or GliNER
- you simply ask any model to extract them (possibly with smart prompting)
- there are models focused on triple extraction and knowledge graph creation like Triplex.
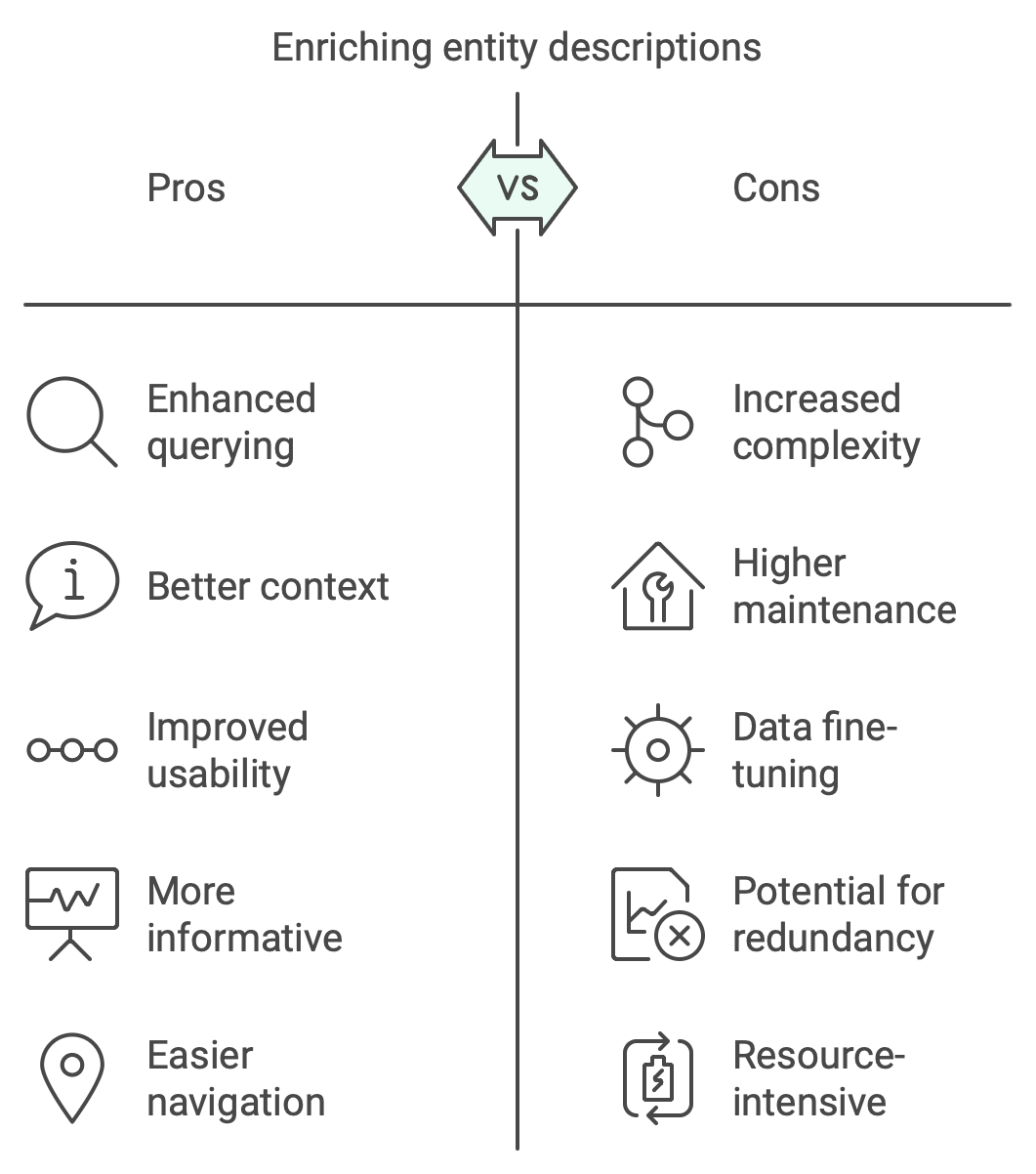
If you extract an entity on its own it does have a pointer to the chunk it came from, but for downstream tasks like querying it’s beneficial to have a description or explanation within the entity. That is, rather than simply extract the name and type of an entity, it’s beneficial to also ask the model what the entity is. For instance, the entity (John, PERSON) is a lot less useful than (John, PERSON, John is a lawyer living in Montana). The thing is of course that the more data becomes available about an entity, the more the description has to be fine-tuned.
Whether or not you have bare entities or you adorn them with context relates to deep issues with knowledge graphs:
- can the KG be incremented easily or does it require the whole corpus?
- how to organize entities in semantically related domains?
- how to ensure that when querying the KG you pick up the correct entity?
Every framework or company has its own view on the matter. Frameworks like Microsoft GraphRAG are not incremental and very expensive in terms of LLM processing. RDF databases rely on ontologies to embed meaning. Like all else, it depends on many factors and what your end game is.
We are early 2025 and in my view, the most efficient way to graph RAG things is the LightRAG approach but who knows how things will be in a few years from now.
Relationships
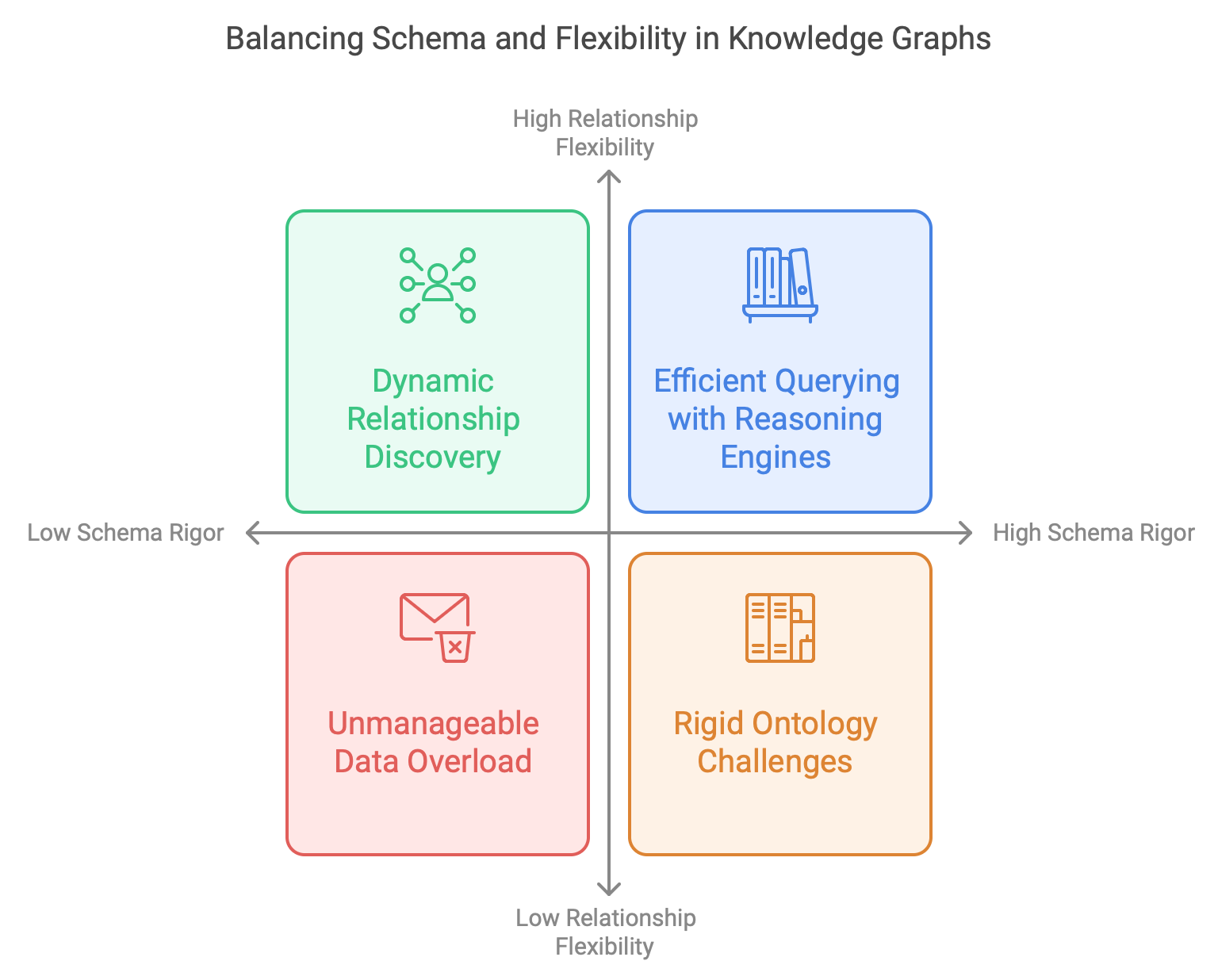
The extraction of relationships within knowledge graphs presents various complexities. A primary consideration revolves around whether entities should conform to a pre-defined schema (ontology) or allow relationships to emerge organically (inferred schema). However, this dichotomy poses a risk: the pursuit of a strictly structured knowledge graph may compromise its querying efficiency. Conversely, a KG without some form of schema can rapidly become an unmanageable repository of information.️
Creating ontologies based on RDF leads to triple stores and you potentially find value in reasoning engines, constraints (SHACL) and lots of things you will not find in the less rigid world of property graphs. My experience is that developing an ontology is a burden and asking domain experts to master ontologies (in order to implement their know-how into an ontology) is often difficult. People find it hard to make a leap of abstraction even if they understand their domain very well. Things like transitivity, superclasses, the difference between object and value properties…are quite abstract for most people and they correctly wonder what the benefits are. Of course, I am not saying that ontologies are useless, just that you have to understand what it entails and where it leads to.
Just like entities, it is useful to embed descriptions in relationships. It’s the alternative to a predefined ontology. Rather than a triple (John, KNOWS, Maria) you can have (John, Maria, John met Maria on the train during a trip to a conference in London). The latter will be more helpful when embedded in a vector while the former will be more useful if you wish to have a pure KG. Reasoning engines will not work without ontologies but the latter form will be better for bot apps.
Utilizing a predefined ontology within the prompt context enables an LLM to generate entities and relationships. This methodology is favored by Neo4j and yields satisfactory results; however, its efficacy is limited when dealing with extensive ontologies, as it may lead to token size truncation. Consequently, this approach is more suitable for tutorial purposes rather than practical applications. Furthermore, if a complex schema is provided for each NER extraction, the process becomes computationally slow due to the LLM’s need to ingest the ontology on every occasion.️
Note that simple predicates also leads to issues with disambiguation. The better approach is to keep a description and use the vector embedding to figure out whether an entity is new or the same. If you only have (John, PERSON) it will be hardly possible to figure out whether the appearance of ‘John’ in a chunk is the same or not from the one already ingested.
Querying Knowledge Graphs
Global and local
The relationships between KB entities can be approached in two ways:
- use vector similarity with respect to the k-nearest nodes and take the attached edges, this is called local querying
- use vector similarity across all edges and take the k-nearest edges with the edge endpoints giving entities, this is called global querying.
If you combine both approaches and merge the results you get hybrid querying.
It can be shown that results are improved if global search occurs with global topics. For instance, the question ‘What did John Field compose in early 1830?’ leads to global topics ‘music, composer, person’ and local keywords ‘John Field, 1830’. Global queries work best with global topics and local search with local keywords.
This is not written in stone, nothing prevents one from using for instance depth-first traversals or multi-hop queries. What works best depends on the KG and the business domain.
Graph analytics
A knowledge graph can be approached like any other graph and various tools can be useful:
- centrality is the answer to the question ‘what are the most important nodes and edges?’, it helps discover dense hubs, uncoupled subgraphs (weakly connected components) and more. These measures can be used during querying to sort results.
- cluster and community detection help identify global topic clusters. Some approaches like Microsoft GraphRAG and Neo4j’s graph builder advocate this approach.
- introducing meta-nodes to organize knowledge in some way. This happens often with respect to a company’s internal organization rathe than purely on the basis of the raw corpus.
Note that certain things require the whole graph and difficult to implement incrementally. Conversely, deleting things in a KG can have a direct impact on topological metrics. You should carefully analyze the long-term impact of certain measures and how they affect a changing KG.
Naive RAG
The Graph RAG model encompasses a basic variant, often referred to as standard or naive RAG. This approach is applicable when a knowledge graph with embeddings is available, allowing for the computation of chunk embeddings against which queries can be posed. Consequently, naive RAG constitutes the fourth query method, alongside local, global, and hybrid approaches. In typical applications, these four options are presented to the end-user.
Notably, naive RAG does not involve the knowledge graph in its operation, thereby rendering it the fastest of the four query techniques.️
Interactions
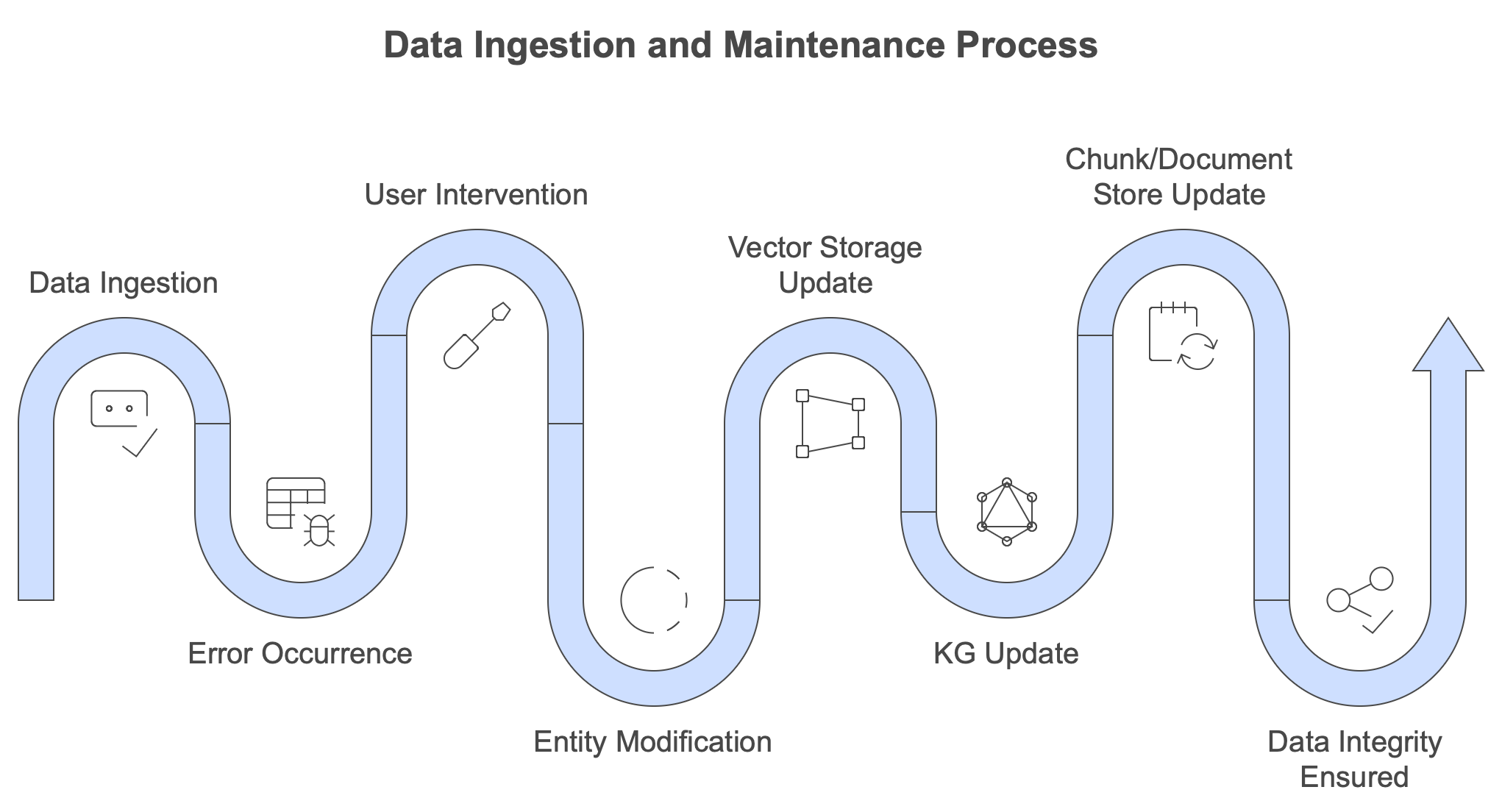
The initial introduction of a dataset into a system or process is a critical phase; however, a thorough examination of the subsequent long-term interactions and consequences is equally essential for a comprehensive understanding.️
Any ingestion will lead to errors and issues. The end-user or domain expert needs to be able to adjust and correct things in the KG. This can take many forms:
- entities and relationships can be deleted
- entities can be added or existing ones adorned (change the description, add keyword)
- chunks might not contain relevant information
- weights can be altered to increate the importance of some relationships.
Each of these actions should update the vector storage, the KG and the chunk/document store:
- when a description is changed, the entity/relationship should be vectorized again
- if a chunk is removed or changed, all stores should get updated
and so on. The central idea here is data integrity or change propagation. On a code level this means that various bits used by the ingestion should be triggered in other ways as well. The CRUD (create/read/update/delete) has to be in place on all levels: document, chunk, node and relationship. Once again, if you understand conceptually how graph RAG hangs together it’s just a lot of coding and unit testing. I mean, it’s not algorithmically demanding, just correct plumbing and wiring of methods.
Minimal setup
In this section I describe a typical POC/MVP, running fully local.
You need three types of data storage:
- for chunks and raw documents (text) you can use JSON files or, more advance, some document database like MongoDB.
- for vectors the ChromaDB is the easiest of them all but any of the ones listed on Wikipedia will do
- for the knowledge graph you can use NetworkX and a file (e.g. GraphML) and a more advanced setup would entail Memgraph, Neo4j, AWS Neptune and many more.
A minimal setup based on files is obviously not going to scale well but can go a long way. You can combine everything in one and the same storage. For instance, Neo4j can store vectors graphs and text at the same time. There are also some open source options like Unum or UStore.
The storage and querying part is straightforward, but depends on the underlying API. You can also explore the wrappers of LlamaIndex and LangChain for inspiration.
Tokenizing can be based on Tiktoken or the Huggingface tokenizer:
ENCODER = tiktoken.encoding_for_model(settings.tokenize_model)
tokens = ENCODER.encode(content)Chunking of documents can be done via tokenizing by taking a fixed amount of tokens each time, or you can use something smarter like semantic chunking. The size of a chunk and what works best depends on the type of data. You don’t need a fixed chunk size, using an amount of sentences can work too. Some advocate the need to have overlapping chunks, with a certain amount of tokens in adjacent chunks.
The most basic fixed token length approach looks like this:
tokens = encode(content)
if len(tokens) <= max_token_size:
return content
else:
return decode(tokens[:max_token_size])The original documents need to be stored with a unique identifier and each chunk has to point to this unique identifier so that grounding and showing references can be done with each request.
Once chunking is done you need to feed each chunk to the ingestion process:
- the entities are extracted with some relations
- every chunk produces a little graph (it can be a single entity, nothing at all or a small graph with a dozen nodes and edges)
- this little graph has to be merged into the global KG
In addition: - every entity and relationship is vectorized - every chunk is vectorized - all the entities and relationships need to point to the chunk where they were found.
The most difficult part here is how to extract this ‘little graph’ from a chunk. As mentioned earlier, the magic resides in a sophisticated prompt. In essence, you ask very explicitly and by giving examples to the LLM what you need. This can look something like this:
--Goal--
You get a piece of text and a list of entity types. Identify all entities of those types from the text and all relationships among the identified entities.
--Steps--
1. Identify the entities:
- the entity name
- the entity type
- a description of this entity
Format each entity as follows:
(entity name, entity type, entity description)
2. From the entities in step 1 identify all pairs that are related.
For each pair (source_entity, target_entity) you extract the following information:
- source_entity: the name as identified in step 1
- target_entity: the name as identified in step 1
- description: a description of this relationship
3. Identify high-level keywords that summarize the essence of the given text.
--Examples--
<give concrete example here>
--Given text--
<inject the chunk here>The magic sauce here is the neatly structured format and the very explicit guidelines and examples.
There are various models which focus on named entity extraction but they typically will not generate the high-level keywords and the description. These are, however, essential for the querying part and for the vectorization. If you leave out these you will generate a typically triple store but the incremental aspect will be much harder.
What happens when the same entity appears in multiple places with a different description? This is the smart merging part. The LLM is used once again to create a comprehensive merge of the description. This idea also applies to the description and keywords on relationships. The trickier part is to identify an entity within a context. For example, if two paragraphs contain the word ‘apple’ and one refers to the company while the other refer to fruit, the merged description will not make sense. There are a few ways to proceed: - you can ask the LLM very clearly whether the two entities with the given descriptions refer to the same thing. - you analytically look at the similarity of the node’s neighborhood - you can use the neighborhood as context to the question for the LLM.
If the LLM thinks the two are the same you can proceed and if not you need to store the entity separately. This could mean that the unique key for a node in the KG is not the name but the combination (name, type) or possibly more. Whether this is necessary depends on the knowledge domain. For example, technical terms like ‘cyanobacteria’ or ‘synechococcus’ are unlikely to refer to more than one thing, but names like ‘phoenix’ or ‘apple’ lead to disambiguation modeling.
The little chunk graphs can be merge in the KG and in addition: - every entity is vectorized together with the description - every relationship is vectorized together with the description and the keywords
All of this can fit in a single Python file. A scalable solution would entail some queues and separate processes. A sophisticated implementation is TrustGraph for instance. A codebase like TrustGraph contains a lot of plumbing code related to Apache Pulsar and other things, meaning that the essence of a graph RAG pipeline is hard to discover. It helps tremendously to have a minimal solution as a map to develop something like TrustGraph.
In any case, at this point the KG is ready to be queried. As mentioned above there are four types and each type has been described. The implementation is quite straightforward, if you understand conceptually what needs to be assembled.
For instance, the local query requires: - fetching the most important nodes via the vector databases - collecting for these nodes the relationships attached (edge neighbors) - collecting the unique chunks - sorting the chunks on the basis of some order, typically the edge degree - using these chunks as context for the question.
It means you need to use the NetworkX API, the ChromaDB API and so on. The fact that these API are very plain makes it easy to see what is graph RAG specific and what is storage specific. Here again, if you use Neo4j, Pinecone, MongoDB and whatnot, you likely will get lost in API’s. Start simple and grow from there.
Appendix
A1 Things to consider
- ontologies in a semantic context are based on OWL/RDF and if you use Protégé for a while you will discover that it can be a vocation to create something great. People often refer to an ontology as an emerging schema (e.g. when using property graphs) or do not understand why it matters. My advice here is to research carefully and consider in advance the pro and contra of an ontology. You can explicitly via smart prompts instruct a LLM to stick to a schema but if your ontology is substantial this will not work (due to the window size). The type of graph database will often help or hinder your schema development. Using TypeDB or TigerGraph enforce a schema from the start, most RDF databases have dynamic inference and reasoning based on OWL, the property graphs typically lack support for ontologies. In this sense, make sure that if you don’t wish to a long ontological journey you also don’t pick a database which enforces it. Equally well, I have seen many developments discover rather late that having some schema is a good things. If you store your graph in MongoDB and a dozen of devs are working with it, you can be certain that the schema will diverge over time.
- if you go big, you need big infrastructure. Systems like Trustgraph use async communication via Apache Pulsar to scale the various elements highlighted above. This is wonderful provided you understand it all and you know that this is necessary. Most customers don’t have petabyte knowledge bases but if one of them does, make sure you focus on scale, cost and performance.
- for medium size developments you might benefit from ETL platforms like Apache Airflow, Apache Hop or (my new favorite) Kestra. Orchestration, logging, security (encryption of chunks for instance) and many other enterprise factors matter. Just don’t let those aspects get in the way of the graph RAG intelligence you are after.
- visualization of knowledge graphs is one of my core competences and if you need assistance with this, gimme a call Graphs beg to be visualized and in many projects it’s essential to have some kind of diagrams.
- the LLM cost is something you need to consider carefully. Development benefits from local setups like Ollama but you will discover that cloud services (like OpenAI, LlamaParse, Vertex AI…) are often cheaper if you wish to ingest large amounts of data. And a lot faster than anything you can achieve on a laptop. There tools on the market to help evaluate cost, like Ragas and DeepEval.
- If you use frameworks like CrewAI you will need LMOps like Arize Phoenix, TrueLens and LangSmith. With a minimal setup you will be able to use standard Python debugging. There is the incorrect perception that one has to use a framework to have (angentic) AI, but that is not the case. I think that implementing graph RAG without a framework will give a deeper understanding and a foundation to proceed (if needed) to these frameworks. There is also the general agreement that frameworks come with lots of things you don’t need. For example, why would you include code for all the different vector databases if you use only one? Frameworks capable of everything are often complex and fixing issues can lead to rabbit holes. Be careful with embracing agent frameworks (this video is interesting in this context).
A2 On clustering and global topics
Extracting a KG from a corpus leads to knowledge on a low level. That is, there is no semantic hierarchy. You can compare it with Wikipedia articles without content organization. There are no topics, you have an index but no table of contents. This works but experiments show that it leads to low accuracy. In addition, some question are about broad topics (What is oncology?) and can’t be answered by having thousands of details (entities).
Frameworks like Microsoft GraphRAG remedy this by post-processing knowledge and use clustering methods like the Louvain algorithm to infer hierarchy. This works but it’s demanding on many levels and requires the whole KG to be present. Incremental intelligence is difficult via this route.
The more scalable approach is to embed description/information within the KG and at query time prompt the LLM for high-level and low-level topics. For example, if the question is ‘When did John Field die?’ the high-level topics would be ‘person, composer, music’ while the low-level keywords would be ‘John Field, death’. The combination bypasses the need for community creation in the KG and it has been shown to be more accurate.
Clustering can have benefits outside RAG and if you want a clean KG, drill-down visualization, ML development (GNN)… clustering is the way to go. Once again, don’t blindly follow the marketing claims and understand how certain choices affect your business aims (app goals).
A3 Document Parsers
Turning documents into text or markdown has become a business avenue on its own. What works best depends on the type of documents you need to parse and on your budget. Documents with charts, tables, maths are more complex than Gutenberg books, legal texts with references, footnotes and complex hierarchies can be hard to chunk. Some parsers combine OCR with computer vision and LLM, some are fast, some can handle noise (smudges), some deal well with many languages…there is a spectrum of solutions and features.
Open Source
- Unstructured The library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of
unstructuredrevolve around streamlining and optimizing the data processing workflow for LLMs. The Unstructured modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs. - LLMSherpa Open source solution tackling generic problems that other parsers have, see this article for an interesting overview.
- Marker focuses on scientific papers and lots of languages.
- Camelot an older but still relevant package.
- Open Parse
- LlmDocParser A package for parsing PDFs and analyzing their content using LLMs.
- Apache Tika See this article looking into the scalability of Tika.
Cloud Services
- LlamaParse is part of LlamaIndex and a closed cloud service.
- Azure Document Intelligence is a cloud service with strict compliance and security, well integrated with other cloud services.
- Amazon Textract much like the Azure service.
A4 Graph RAG Frameworks
- Microsoft Graph RAG
- Formerly Neo4j GenAI but now called Neo4j GraphRAG for Python
- Nano Graph RAG
- LightRAG
- Fast Graph RAG
- TrustGraph